Recientemente en mi trabajo la concurrencia se ha vuelto el pan de cada día, incluso el de varios de mis compañeros. En esta entrada definiré lo que es la concurrencia y cómo esta se diferencia del multithreading y el multiprocessing. Dado que estos conceptos no son tan fáciles de digerir, dejaré el ejemplo práctico que es habitual en mis entradas para otro día (sorry!).
¿Qué es la Concurrencia?
Imagina que eres un chef con su propio restaurante; estando en la cocina es posible que tengas más de una orden que preparar, sin embargo, no vas a preparar una tras de otra, eso sería demasiado lento y tus clientes se irían a un McDonalds. Te das cuenta de que cada orden tiene “tiempos muertos”, es decir, una etapa que sí o sí consume tiempo y no puedes hacer nada para acelerar el proceso, como por ejemplo hervir una papa. Sería una perdida de tiempo esperar sin hacer nada a que la papa se cocine, es por eso que decides picar los vegetales mientras la papa se cocina.
Exactamente en eso consiste la concurrencia: alternar entre tareas. Observa que si bien dos tareas están ocurriendo al tiempo (cocer la papa y cortar los vegetales), solo una de ellas tiene tu atención (cortar los vegetales). La CPU funciona muy similar; hoy en día los procesadores tienen más de un núcleo y estos núcleos tienen hilos. Dentro de un hilo pueden ejecutarse muchas tareas a la vez utilizando la concurrencia o solo una tarea por hilo (multithreading). Para verlo más claro, observa la siguiente imagen:
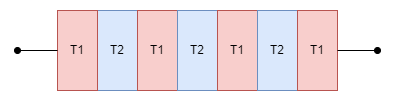
Lo que estás observando representa un hilo con dos tareas, la tarea T1 de color rojo y la tarea T2 de color azul. Ambas tareas requieren procesamiento, pero no es posible que ambas se ejecuten al tiempo, es por eso que deciden compartir su tiempo en el procesador.
Es importante resaltar que tal vez la tarea T1 y la tarea T2 no tengan nada que ver, de hecho esto suele ser lo común. Por ejemplo, la tarea T1 puede ser tu navegador de Internet y la tarea T2 tu editor de texto favorito. Ambos programas tienen contextos diferentes; lo que es lo mismo a decir que tienen instrucciones y direcciones de memoria diferentes. Para que tu procesador no se pierda entre tantos contextos y en tu editor de texto no aparezca contenido de tu navegador de Internet, el procesador realiza un proceso intermedio llamado context switching o cambio de contexto en español. Este proceso normalmente consume una pequeña (imperceptible) cantidad de tiempo en llevarse a cabo y es estrictamente necesario para que se dé la concurrencia. En programas de alto rendimiento se tienden a reducir al máximo los cambios de contexto.
Entonces, ¿Todo esto quiere decir que hemos vivido engañados toda nuestra vida?, ¿La ilusión de que dos cosas están sucediendo al mismo tiempo es solo un efecto que se consigue alternando muy rápidamente entre dos tareas? Bueno… Sí y no.
Un procesador es capaz de ejecutar dos (o más) tareas exactamente al mismo tiempo, esto se conoce como multithreading. Sobre esto hablo en la siguiente sección.
Sin embargo, solo porque algo sea posible no significa que sea la mejor opción. No es muy recomendable emplear todo un hilo en un núcleo solo para una tarea porque le estaríamos quitando la oportunidad a otras tareas de ejecutarse; en caso de que la tarea consumiendo todo el hilo sea demasiado pesada, esto haría que otras tareas tarden más nada más para poder empezar a ser ejecutadas y eso no sería muy justo. Por ejemplo, imagina la fila de un banco: solo hay una caja habilitada y la persona que está en ella se está tomando todo el tiempo del mundo para realizar sus transacciones, sin embargo, hay muchísima más gente esperando nada más para poder empezar a realizar sus transacciones.
¿Qué es el multithreading?
En la sección anterior exploramos el concepto de concurrencia, sin embargo, no es la única manera de hacer dos o más cosas al mismo tiempo. Recordemos que la concurrencia es la habilidad de alternar entre dos o más tareas, pero no de realizar ambas al mismo tiempo; para lograr lo segundo necesitaremos otra estrategia: el famoso multithreading.
Siguiendo con el ejemplo de la sección anterior, imagina que tu restaurante ha crecido y ahora tienes a otro chef que te ayuda a elaborar las órdenes, ahora sí es posible que tú te dediques a cortar vegetales y el otro chef se dedique a cocinar papas; ya no hay necesidad de alternar entre tareas. Para verlo mejor, observa la siguiente imagen:
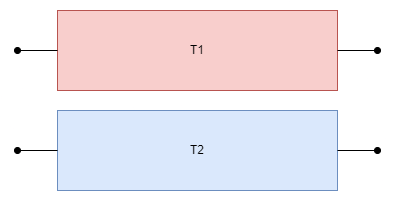
Cada chef representa un hilo, en este caso hay dos hilos y cada uno está exclusivamente dedicado a una sola tarea; el hilo de arriba está dedicado a la tarea roja T1 y el hilo de abajo está dedicado a la tarea azul T2. No hay necesidad de cambiar de contexto debido a que el hilo no se está compartiendo entre dos tareas.
Como mencioné en la sección anterior, esto tiene sus pros y sus contras. Siguiendo el ejemplo del restaurante, tu chef que se dedica a cocinar papas tiene tiempos muertos mientras que una papa se cocina y mete la otra; mientras podrías hacer que pele las zanahorias y así podrías incrementar mucho más la velocidad de tu cocina.
Como dato curioso de esta sección, quisiera hablar sobre la relación entre paralelismo y multithreading debido a que existen muchas personas que piensan que son lo mismo y no, no lo son. Para empezar, hay que tener claro que una CPU puede tener un único núcleo y dentro de ese núcleo tener muchos hilos; eso mis amigos es multithreading. Por otro lado, si en vez de un núcleo se tiene dos o más núcleos, es posible ejecutar programas de manera paralela. Para dejarlo claro, la única manera de tener un verdadero paralelismo es en procesadores con más de un núcleo.
¿Qué es el multiprocessing?
Antes de definir al multiprocessing es importante primero hacerse la pregunta de qué es un proceso.
Un proceso no es más que un programa que ha sido despachado al procesador para su ejecución. Un proceso puede tener uno o muchos hilos dentro de él, de hecho se suelen definir a los hilos como segmentos de un proceso. Por ejemplo, cuando ejecutas tu navegador de Internet estás iniciando un proceso y ese proceso a la vez está iniciando varios hilos por debajo que hacen más cosas.
Un proceso no solo tiene hilos, también tiene un espacio de memoria asignado. Este espacio de memoria no puede (en teoría) ser accedido por otros procesos o por otros hilos que no pertenezcan a ese proceso. Digo en teoría porque es una vulnerabilidad muy común que un proceso sea atacado por otros procesos maliciosos (o simplemente por accidente). Puedes imaginarte un proceso como la siguiente imagen:
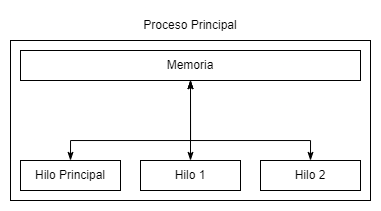
Como mencioné antes, un proceso consiste de un espacio de memoria y uno o muchos hilos. En el diagrama anterior podemos observar que el “proceso principal” tiene su reglamentario hilo principal y otros dos hilos; todos estos hilos comparten la misma memoria y esto hace posible que se presenten ciertos problemas a la hora de sincronizar los hilos. Por ejemplo, imagina que tienes una variable contadora llamada X, cada hilo lo que hace es incrementar esta variable en uno (X++) sin embargo, para incrementar su valor primero hay que saber qué valor hay en la variable y es aquí dónde la cosa se pone interesante.
El hilo principal, cuando consulte el valor de X esta podrá tener el valor de cero, sin embargo, mientras el hilo principal estaba leyendo la variable, otro hilo cambió la variable y resulta que ahora el valor de X es uno; cuando el hilo principal vaya a mutar el valor de X este será uno cuando debió ser dos. Lo que acabas de observar es el clásico ejemplo de sincronización entre hilos llamado una condición de carrera o race condition; no te alarmes, tiene solución, sin embargo, no entraré en eso porque alargaría demasiado esta entrada. Solo lo menciono para que tengas en cuenta que un gran poder conlleva una gran responsabilidad.
Teniendo claro lo que es un proceso, es posible definir al multiprocessing como otra estrategia para lograr multithreading. La razón por la cual optarías por una estrategia multiprocessing es porque normalmente los sistemas operativos (o los runtimes de lenguajes de programación) imponen un límite sobre cuántos hilos puedes crear.
Su funcionamiento es muy sencillo: un proceso principal es capaz de crear (o spawnear) a otros procesos llamados procesos hijos, como se observa en la siguiente imagen:
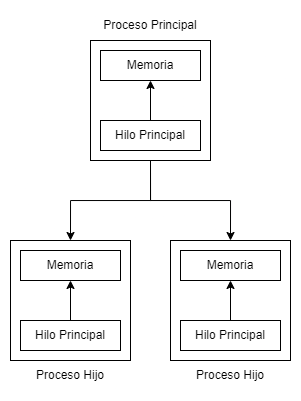
Los procesos hijos tienen su propio espacio de memoria asignado y sus propios hilos; esto permite una separación de la memoria haciendo que sea más difícil “pegarte un tiro en el pie”. Estos procesos a su vez pueden crear más hilos o ¡incluso más procesos!
La comunicación entre estos procesos no es algo tan trivial y si se quiere hacer bien se tienen que seguir ciertas reglas, sin embargo, esta entrada ya se hizo muy larga y tengo mucho sueño. Tal vez en otra oportunidad entre a estos detalles.
Conclusión
La concurrencia es alternar entre dos o más tareas pero no ejecutarlas al mismo tiempo; el multithreading es ejecutar dos o más tareas al mismo tiempo, sin embargo, no es considerado un proceso paralelo y el multiprocessing es la capacidad de balancear el trabajo de un programa entre dos o más procesos que su vez tienen un espacio de memoria propio y otros hilos.
Estas tres estrategias son muy poderosas, sin embargo, ningún poder es gratis. Como mencioné a lo largo del artículo, existen varios escenarios sobre los cuales un programador debe prestar especial atención para no crear un mounstro; no es por nada que los programas concurrentes/multithreading tienen la fama de ser exageradamente difíciles de debuggear.
Tengo mucho sueño para seguir escribiendo, pero creo que ya tienes la idea. Cualquier inquietud en la sección About puedes encontrar mis datos de contacto para seguir hablando.
Dedicado
A la persona más interesante que he conocido recientemente: L.